El internet de las cosas (porcinas) (1/2)
23-jul-2015 (hace 11 años 2 días)
Nuestro sector está a punto de recibir una nueva revolución que probablemente tarde menos en implantarse de lo que pensamos, entre otras por una razón muy sencilla: es algo que viene desde otros aspectos de la vida a la que la ganadería y la producción porcina en general no es ajena. Se trata de la nueva gestión de la información.
Esta evolución se apoya en 4 conceptos que al interactuar redefinirán muchos aspectos de nuestro negocio y son:
- La conectividad-movilidad
- La nube
- Big Data o datos masivos
- Sistemas de Inteligencia de negocio como nuevas herramientas de análisis
¿Y por qué todos estos conceptos que parecen ajenos a nuestra actividad van a marcar la evolución de nuestro sector en los próximos años? Porque están los suficientemente maduros, son lo suficientemente baratos y sencillos como para poder empezar a implementarse en nuestro sector, empezando casi siempre por aquellos productores con mentalidad más profesional (lo que no necesariamente está relacionado con el tamaño, sino con la actitud).
Hasta ahora cuando hablamos de gestión de datos, de manera casi inconsciente lo ligamos a datos de los animales y dentro de estos a los de reproductoras. Eso es básicamente lo que se entiende por ese concepto y quizá también puedan incluirse los datos económicos, aunque esto siempre desde un enfoque propio e interno (o dicho de otra manera, generalmente ni se recogen, ni se analizan ni se comparten más allá del ámbito de la propia empresa, algo que si ocurre con los datos reproductivos). Pero esto va a empezar a cambiar rápidamente, por dos razones:
- Necesitamos trabajar de manera más minuciosa y precisa en otras áreas relacionadas con datos animales (monitorización de la sanidad, control de la bioseguridad, uso de antibióticos o del pienso entre otros)
- Empezamos a disponer de máquinas y dispositivos que generan datos de continuo sin intervención humana.
En cuanto al primer punto, tanto por cuestiones técnicas, de control de calidad interno, estratégicas de la empresa o regulatorias, la cantidad y la frecuencia de los datos gestionados se va a incrementar notablemente. Esto supondrá un esfuerzo del personal encargado de esta tarea y se utilizarán diferentes sistemas a tal fin, desde los clásicos partes de recogida en papel para su procesado posterior, bolígrafos digitales, PDA’s hasta aplicaciones web instaladas en teléfonos móviles o tabletas; todas ellas pueden ser validas según el fin y el usuario.
Pero quizá el cambio más profundo va a provenir de sistemas capaces de generar datos continuamente y sin intervención humana (es lo que se ha venido a llamar ‘el internet de las cosas’), entre los que se encuentran los siguientes:
- Máquinas electrónicas de alimentación de reproductoras en gestación mediante chip
- Controladores de alimentación de reproductoras en lactación, acoplables al bajante del pienso
- Máquinas electrónicas de pesaje de animales y control de la alimentación en cerdos de engorde
- Sensores de temperatura, humedad relativa, CO2, consumo de agua y consumo eléctrico
- Dispositivos de pesaje a distancia mediante tecnología de imagen 3D
- Analizadores automáticos de la calidad del semen integrados en iPad
Todos estos dispositivos, que ya están en el mercado algunos desde hace años, generan enormes cantidades de datos normalmente infrautilizados; por ejemplo, las máquinas de alimentación electrónica de cerdas en gestación, generalmente no se utilizan para mucho más que para saber si una cerda ha comido lo que debía o no.
Ante esta situación los productores y técnicos han de decidir respecto del punto I), si generar datos o no y respecto del punto II, tendrán que decidir si utilizar los datos ya generados o no (se recogen automáticamente). Para ambas preguntas las respuestas más probables serán ‘Si’ (SÍ se van a generar y SÍ se van a utilizar). Por tanto, mejor empezar a pensar en cómo afrontar este escenario con la mayor eficiencia y menor coste posible.
Cualquier productor profesional de porcino (casi diríamos que cualquier empresa), debe abordar el siguiente esquema (gráfico 1) para una correcta gestión de datos y análisis de productividad.
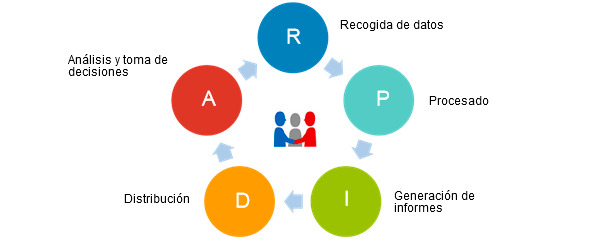
Gráfico 1. Ciclo de optimización de la gestión de datos.
Este esquema generalmente no está optimizado (no sólo en granjas familiares o cooperativas medianas, sino que también en muchas grandes empresas se encuentran importantes lagunas). Así, es muy frecuente que:
- los datos no se recojan bien (ni sean los adecuados ni con la frecuencia adecuada)
- que no se procesen bien (por no disponer de las herramientas necesarias -paquetes de software porcino óptimos a cada situación- o por no disponer del conocimiento o del tiempo necesario)
- que no generen los informes esperados por tipo, por forma o por frecuencia (muchas veces llegan tarde o en un formato impropio)
- que no se distribuyan bien (el informe ha de llegar a la persona adecuada, en la forma adecuada y en el momento oportuno; por ejemplo una lista de cerdas hipoproductivas para desviejar que llegue al trabajador cuando ya han sido cubiertas resulta perfectamente inútil)
- que no se comprendan bien y no se tomen las decisiones que el informe esta ‘pidiendo’, generalmente ocurre por falta de tiempo y de preparación de las personas encargadas. La información está ahí pero no ‘penetra’ en la persona responsable de tomar las decisiones. Por tanto, o no se toman o no se toman las decisiones adecuadas. Esta situación es muy frecuente porque en las empresas actualmente no existe la figura del “analista responsable”, que es el encargado de comprender los informes en producción y aplicar las medidas necesarias. En otras palabras, a falta de la figura del “analista”, cada uno se busca la vida como puede para hacer su trabajo lo mejor posible.
Los primeros análisis de esta enorme masa de datos (generados de manera automática), revelan información de gran interés hasta ahora desconocida. Esto que ocurre con los datos clásicos reproductivos (en PigCHAMP hemos podido predecir el rendimiento de la vida completa de la reproductora en base a los resultados del primer parto mediante el análisis de medio millón de cubriciones de manera meticulosa –Lida, Piñeiro y Koketsu, 2015-),y parece que va a ocurrir también con los datos generados por las diferentes máquinas. Cuando se procesan bien y se analizan adecuadamente muestran todo el valor (información) que ocultan. Este valor de la información es mucho mayor cuando cruzamos datos provenientes de diferentes fuentes, por ejemplo, datos reproductivos con datos de máquinas de alimentación. Nuestros primeros resultados aún sin publicar, muestran algunos efectos de gran importancia hasta la fecha no descritos y que presentaremos en próximos artículos.